AI(機械学習)やってみた、第2弾です。前回は決定木(Decision Tree)を使ったソムリAI(ワインソムリエAI)を作りました。今回は「ロジスティック回帰(Logistic Regression)」というモデルを使ったソムリAIを作ってみようと思います。
第1回ソムリAI ~決定木編~ はこちら↓
うん、よくわからないですね。例えば家を選ぶときには、広さ・間取り・築年数・駅までの距離・周辺施設など様々な要素(変数)があり、人によってそれぞれの要素の重要度(重み)が違うと思います。それを定量的なモデルにするイメージです。
「多少狭くてもいいから駅チカがよくて、できれば新築」という場合は、駅までの距離:1.0・地区年数:0.7・広さ:0.3・・みたいな重みをつけて、重要度の高い要素は強調・低い要素は抑制してスコアリングすることでより好みにマッチした物件が抽出されるような感じです。
今回の例では、アルコール度数や酢酸濃度などのワインを構成する変数をxとし、それぞれの変数に掛ける重みwを機械学習でチューニングして、ワインの評価yを当てる確率の高いモデルを作るということになります。最終的にはw0+w1x1+w2x2+w3x3+・・+wnxnみたいな重みと各変数を掛け合わせた最適モデル(重回帰分析のモデル)を作り、そのモデルをロジスティック関数なるものに突っ込んで目的変数yを当ててやろうということなのです。(w1x1とは、1個目の変数であるx1に、機械学習でチューニングしたx1専用の重み(w1)を掛けた値を示します)
 Pythonではこんなコードで簡単に描画できます。
Pythonではこんなコードで簡単に描画できます。

yは0から1の範囲であり、xが増えるに従って急速にyが大きくなり、xがある程度大きくなるとサチります。一定以下の値ではOFF・一定以上の値でONというON/OFFの関係を滑らかに表現できます。これを使って「ある程度の刺激を受けると活性化する」という神経細胞の働きを表現できたりするようです。
今回やるのは上記のロジスティック関数の公式におけるxに対して、重み付けしたモデル(w0+w1x1+w2x2+w3x3+・・+wnxn)を突っ込んでy(ワインの評価)を最適化するということに挑戦します。なにやら小難しいですが、Pythonで書くと難しいところはライブラリが勝手にやってくれるのでコード自体は単純です。(実は、コード書いてから後づけでロジスティック回帰について学んだので、上記の記載に誤りがあるかもしれません。。)
◆参考にしたサイト◆
まず入力データとなる赤ワイン1600本分のデータを読み込みます。
 結果(黄色にハイライトしている箇所)を見ると、訓練データでは58%の精度ですが、検証用データでは訓練データを上回る63%の精度が出ています。訓練データで作ったモデルで検証データを正しく判断できている(過学習が発生していない)ので、よいモデルができたということです!決定木版のソムリAIの精度が59%だったのでロジスティック回帰の方が若干精度の高いモデルになりました。
結果(黄色にハイライトしている箇所)を見ると、訓練データでは58%の精度ですが、検証用データでは訓練データを上回る63%の精度が出ています。訓練データで作ったモデルで検証データを正しく判断できている(過学習が発生していない)ので、よいモデルができたということです!決定木版のソムリAIの精度が59%だったのでロジスティック回帰の方が若干精度の高いモデルになりました。
 結果は、絶対値順に「酢酸濃度」「クエン酸濃度」「アルコール度数」がトップ3でした。なかでも「酢酸濃度」の絶対値が突出して大きく、ロジスティック回帰版のソムリAIは「酢酸濃度」を重視しているようです。決定木版のソムリAIの決定係数は「アルコール度数」「硫化カリウム濃度」「酢酸濃度」の順であり、モデルによる違いが見れて面白いですね。
結果は、絶対値順に「酢酸濃度」「クエン酸濃度」「アルコール度数」がトップ3でした。なかでも「酢酸濃度」の絶対値が突出して大きく、ロジスティック回帰版のソムリAIは「酢酸濃度」を重視しているようです。決定木版のソムリAIの決定係数は「アルコール度数」「硫化カリウム濃度」「酢酸濃度」の順であり、モデルによる違いが見れて面白いですね。
まずは入力データから。
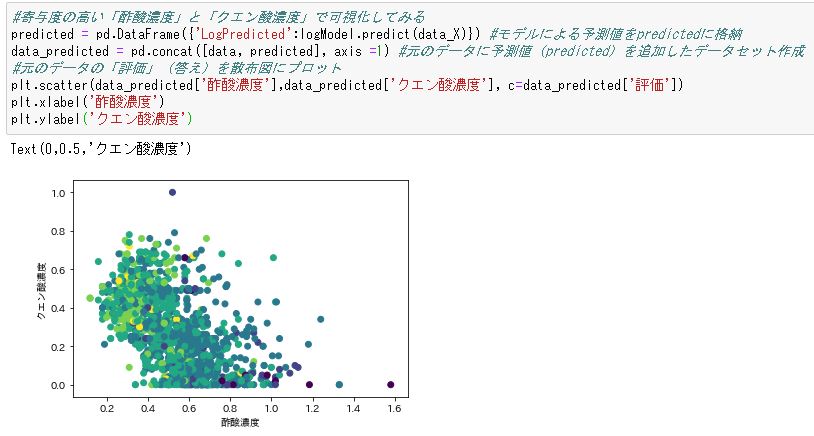 各点の色は「評価」を表しています。うーん、青と薄い青と黄緑でうっすら縞模様になっているようにも見えますが、ごちゃっとしていますね。11個の変数で決まるモデルを2次元で描くのには限界があるかもしれません。
各点の色は「評価」を表しています。うーん、青と薄い青と黄緑でうっすら縞模様になっているようにも見えますが、ごちゃっとしていますね。11個の変数で決まるモデルを2次元で描くのには限界があるかもしれません。
次にモデルがはじき出した予測値をプロットしてみます。
 お、少し色合いが代わりましたね。青系の点と紫の点の境界がはっきりしました。また、左下から右上方向に散布する黄色い点の帯がうっすらと見えます。ロジスティック回帰でモデル化することで実測値(入力データ)では曖昧だった境界がよりクリアになったのかもしれません。
お、少し色合いが代わりましたね。青系の点と紫の点の境界がはっきりしました。また、左下から右上方向に散布する黄色い点の帯がうっすらと見えます。ロジスティック回帰でモデル化することで実測値(入力データ)では曖昧だった境界がよりクリアになったのかもしれません。
最後に入力データとモデルの予測値を重ね合わせて見ます。1つ工夫して、モデルの予測値のマーカーをxにしています。こうすることで入力データと予測値の「評価」が異なる(=散布図上の点の色が異なる)場合、xが浮き上がって見えます。
 うん、でもやっぱりごちゃごちゃしていますね。
うん、でもやっぱりごちゃごちゃしていますね。
1600のデータをプロットするには限界がありそうなので、500個に絞って描画してみます。散布図描画の1個目のコード(Step 4の1個目の描画処理)に太字の1行を追加して、描画処理を再実行します(他の部分は修正なし)。
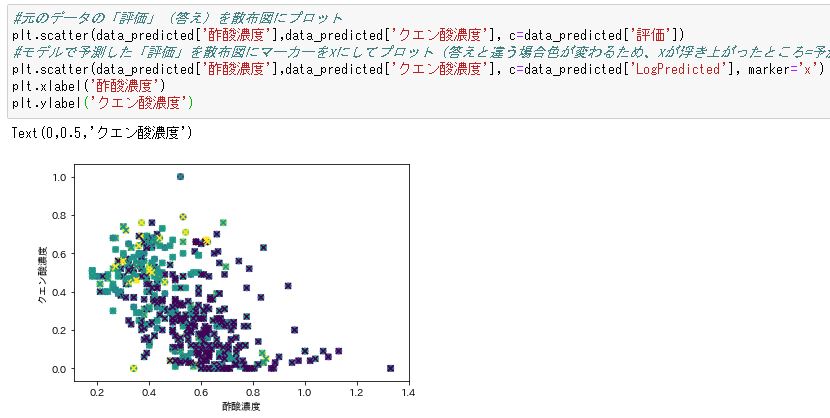 予想通り、入力データと予測値で傾向の異なった紫色のxが多く見られます。これはモデルが紫と予測したものの、実際の評価は青や薄い青・黄緑であったことを示しています。
予想通り、入力データと予測値で傾向の異なった紫色のxが多く見られます。これはモデルが紫と予測したものの、実際の評価は青や薄い青・黄緑であったことを示しています。
11個の(11次元の)データを2次元でプロットしたので少し無理はありましたが、ぼんやり傾向は見えたように思います。
次回はニューラルネットワーク版のソムリAIを作ってみようと思います。
第1回ソムリAI ~決定木編~ はこちら↓


ロジスティック回帰とは
ロジスティック回帰は多変量解析(多くの変数を扱う分析)に適した手法です。ものすごく雑にざっくり言うと、「複数の変数x1, x2, x3,・・,xnに対してそれぞれ重みw1, w2, w3,・・, wnを掛け合わせて目的変数yになる確率が高いモデルをロジスティック関数というものを使って作ろう」ということです。うん、よくわからないですね。例えば家を選ぶときには、広さ・間取り・築年数・駅までの距離・周辺施設など様々な要素(変数)があり、人によってそれぞれの要素の重要度(重み)が違うと思います。それを定量的なモデルにするイメージです。
「多少狭くてもいいから駅チカがよくて、できれば新築」という場合は、駅までの距離:1.0・地区年数:0.7・広さ:0.3・・みたいな重みをつけて、重要度の高い要素は強調・低い要素は抑制してスコアリングすることでより好みにマッチした物件が抽出されるような感じです。
今回の例では、アルコール度数や酢酸濃度などのワインを構成する変数をxとし、それぞれの変数に掛ける重みwを機械学習でチューニングして、ワインの評価yを当てる確率の高いモデルを作るということになります。最終的にはw0+w1x1+w2x2+w3x3+・・+wnxnみたいな重みと各変数を掛け合わせた最適モデル(重回帰分析のモデル)を作り、そのモデルをロジスティック関数なるものに突っ込んで目的変数yを当ててやろうということなのです。(w1x1とは、1個目の変数であるx1に、機械学習でチューニングしたx1専用の重み(w1)を掛けた値を示します)
数学が苦手な文系エンジニア(僕)のための備忘
もう少し補足をすると、ロジスティック関数とは下記の式で表されるS字型の関数です(正確には「狭義のシグモイド関数」と言うらしい)。僕には呪文にしか見えません。。
#ライブラリimport
import numpy as np
import matplotlib.pyplot as plt
#ロジスティック関数のクラス定義
def logistic_function(x):
return 1/ (1+ np.exp(-x)) #数式の定義
#描画
x = np.linspace(-5,5) #xを-5から5まで変化させる
plt.plot(x, logistic_function(x)) #ロジスティック関数を描画
plt.xlabel("x") #x軸ラベルの設定
plt.ylabel("y") #y軸ラベルの設定
yは0から1の範囲であり、xが増えるに従って急速にyが大きくなり、xがある程度大きくなるとサチります。一定以下の値ではOFF・一定以上の値でONというON/OFFの関係を滑らかに表現できます。これを使って「ある程度の刺激を受けると活性化する」という神経細胞の働きを表現できたりするようです。
今回やるのは上記のロジスティック関数の公式におけるxに対して、重み付けしたモデル(w0+w1x1+w2x2+w3x3+・・+wnxn)を突っ込んでy(ワインの評価)を最適化するということに挑戦します。なにやら小難しいですが、Pythonで書くと難しいところはライブラリが勝手にやってくれるのでコード自体は単純です。(実は、コード書いてから後づけでロジスティック回帰について学んだので、上記の記載に誤りがあるかもしれません。。)
◆参考にしたサイト◆



ソムリAI(ロジスティック回帰版)を作ってみる
Step 1: 機械学習の前準備(データの整形など)
前準備でやることはソムリAI(決定木版)と同じです。簡単にコードだけ再掲します。まず入力データとなる赤ワイン1600本分のデータを読み込みます。
#入力データセットを読み込み
import pandas as pd #データハンドリング用ライブラリ呼び出し
data = pd.read_csv('winequality-red.csv', encoding='SHIFT-JIS')
data.head() #先頭5つを表示して読み込まれていることを確認
次に、入力データをアルコール度数などの「モデル作成に使うインプットデータ」と「モデルを検証するための解答データ」であるワインの評価に分割します。解答データを「教師データ」と呼んだりもします。#機械学習で求める解である「評価」以外の項目をdata_Xに、「評価」をdata_Yに格納 data_X = data.copy() del data_X['評価'] data_Y = data['評価'] data_X.head() #評価欄がないことを表示して確認 data_Y.head() #評価欄のみであることを表示して確認最後に、用意したデータを「モデルを作るためのデータ」と「モデルを検証するためのデータ」に分けます。前回同様、元データの70%をモデルを作るためのデータ(訓練データ)・残りの30%をモデルを検証するためのデータ(検証データ)にします。これで事前準備はおしまいです。
#入力データセットの70%を訓練データ・30%を検証データに分割 from sklearn.model_selection import train_test_split #機械学習用ライブラリ呼び出し X_train, X_test, Y_train, Y_test = train_test_split(data_X, data_Y,random_state=0, test_size=0.3) print(len(X_train)) #訓練用のデータ数を表示(70%) print(len(X_test)) #検証用のデータ数を表示(30%)
Step 2: ロジスティック回帰を使った機械学習
いよいよロジスティック回帰によるモデル作成です。機械学習用のライブラリであるScikitlearnからLogisticRegressionというロジスティック回帰関数を呼び出し、訓練データを使って機械学習させます。fitという関数(メソッド?)に訓練データを突っ込むだけでモデルができます。なんて便利!最後に訓練データでのモデルの精度と、作成したモデルを検証用データに適用した場合の精度を表示させます。#ロジスティック回帰による機械学習 from sklearn.linear_model import LogisticRegression#機械学習用ライブラリからロジスティック回帰を呼び出し logModel = LogisticRegression()#モデル定義 logModel.fit(X_train, Y_train)#機械学習実行(訓練用データを使ったモデル生成) print(metrics.accuracy_score(Y_train, logModel.predict(X_train))) #訓練データの精度表示(訓練データ用のモデルでどの程度訓練用データの「評価」を当てられるか) print(metrics.accuracy_score(Y_test, logModel.predict(X_test))) #検証用データの精度表示(訓練データ用のモデルでどの程度検証用データの「評価」を当てられるか)
Step 3: 変数の重要度(重み)の検証
モデルができたので、中身を紐解いていこうと思います。各変数の重要度(重み)を表示してみましょう。#モデルの決定係数を表示(入力データの各項目の寄与度を表示)
Coef = pd.DataFrame({'変数名':data_X.columns, '寄与係数':logModel.coef_[0]})
Coef.sort_values('寄与係数') #絶対値が大きいほどモデルにおける重みが大きい(+は評価を上げる効果・-は下げる効果)
Step 4: データの可視化
百聞は一見にしかずということで、データの可視化をしてみようと思います。「アルコール度数」などの変数は全部で11個あるので正しく表示するには11次元の表が必要なのですが、そんなもの描けっこないのでモデルへの寄与度の高い「酢酸濃度」と「クエン酸濃度」で平面の散布図を描いてみようと思います。まずは入力データから。
#寄与度の高い「酢酸濃度」と「クエン酸濃度」で可視化してみる
predicted = pd.DataFrame({'LogPredicted':logModel.predict(data_X)}) #モデルによる予測値をpredictedに格納
data_predicted = pd.concat([data, predicted], axis =1) #元のデータに予測値(predicted)を追加したデータセット作成
#元のデータの「評価」(答え)を散布図にプロット
plt.scatter(data_predicted['酢酸濃度'],data_predicted['クエン酸濃度'], c=data_predicted['評価'])
plt.xlabel('酢酸濃度')
plt.ylabel('クエン酸濃度')
次にモデルがはじき出した予測値をプロットしてみます。
#モデルで予測した「評価」を散布図にプロット
plt.scatter(data_predicted['酢酸濃度'],data_predicted['クエン酸濃度'], c=data_predicted['LogPredicted'])
plt.xlabel('酢酸濃度')
plt.ylabel('クエン酸濃度')
最後に入力データとモデルの予測値を重ね合わせて見ます。1つ工夫して、モデルの予測値のマーカーをxにしています。こうすることで入力データと予測値の「評価」が異なる(=散布図上の点の色が異なる)場合、xが浮き上がって見えます。
#元のデータの「評価」(答え)を散布図にプロット
plt.scatter(data_predicted['酢酸濃度'],data_predicted['クエン酸濃度'], c=data_predicted['評価'])
#モデルで予測した「評価」を散布図にマーカーをxにしてプロット(答えと違う場合色が変わるため、xが浮き上がったところ=予測失敗したもの)
plt.scatter(data_predicted['酢酸濃度'],data_predicted['クエン酸濃度'], c=data_predicted['LogPredicted'], marker='x')
plt.xlabel('酢酸濃度')
plt.ylabel('クエン酸濃度')
1600のデータをプロットするには限界がありそうなので、500個に絞って描画してみます。散布図描画の1個目のコード(Step 4の1個目の描画処理)に太字の1行を追加して、描画処理を再実行します(他の部分は修正なし)。
#寄与度の高い「酢酸濃度」と「クエン酸濃度」で可視化してみる
predicted = pd.DataFrame({'LogPredicted':logModel.predict(data_X)}) #モデルによる予測値をpredictedに格納
data_predicted = pd.concat([data, predicted], axis =1) #元のデータに予測値(predicted)を追加したデータセット作成
data_predicted = data_predicted.head(500) #対象データを先頭から500個に絞る
11個の(11次元の)データを2次元でプロットしたので少し無理はありましたが、ぼんやり傾向は見えたように思います。
まとめ
- ロジスティック回帰の方が決定木より若干精度の高いモデルになった。
- モデルにおける各変数の重みである決定係数の順位・重さが決定木とロジスティック回帰で異なる結果となった。
- Pythonで実装するのはそこまで難しくないが、ロジスティック回帰の数学的な理解はとっても難しい(自分への戒め)。
次回はニューラルネットワーク版のソムリAIを作ってみようと思います。




























