乳がん診断AI第二弾です。前回に引き続き、ランダムフォレスト・多数決などのアルゴリズムを使って精度を確認していきます。前回、ニューラルネットワークが叩き出した診断精度95%を大きく超える結果になりました!
まずは、決定木・ニューラルネットワーク・ロジスティック回帰・ランダムフォレストの機械学習アルゴリズムに対して、機械学習の訓練データと検証データを入れ替えながら学習することで精度を高める交差検証を試してみます。各アルゴリズムの概要や交差検証については、ソムリAIで解説していますので興味のある方は見てみてください(下にリンクを貼っています)。
ソムリAIの時と同様、決定木・ロジスティック回帰・ニューラルネットワーク・ランダムフォレストのモデルを定義して、交差検証用の関数に放り込みます。データの分割数は3分割~10分割として交差検証を行い、最適な分割数を求めようと思います。
決定木とニューラルネットワークについては、前回探索したハイパーパラメータを設定しています。ロジスティック回帰については適当に設定したパラメータで結果的に精度が出たのでそれを使っています。ランダムフォレストはフォレスト(森)に使う決定木の本数が多いほど精度が出るのでとりあえず100本にしています。
 モデルによってでこぼこしていますが、6分割の交差検証の平均スコアが一番良さそうです。決定木で92%・ロジスティック回帰で97%・ニューラルネットワークで96%・ランダムフォレストで95%とかなりいい感じです。ただ、精度の低い決定木を除外すると最適な分割数も変わるような気もするので後で試してみようと思います。
モデルによってでこぼこしていますが、6分割の交差検証の平均スコアが一番良さそうです。決定木で92%・ロジスティック回帰で97%・ニューラルネットワークで96%・ランダムフォレストで95%とかなりいい感じです。ただ、精度の低い決定木を除外すると最適な分割数も変わるような気もするので後で試してみようと思います。
 決定木95%・ロジスティック回帰97%・ニューラルネットワーク95%・ランダムフォレスト96%とかなり高い精度が出ました。
決定木95%・ロジスティック回帰97%・ニューラルネットワーク95%・ランダムフォレスト96%とかなり高い精度が出ました。
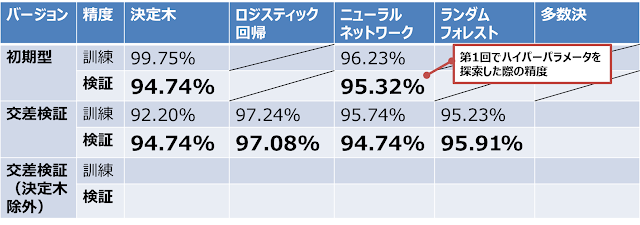


 一番下の多数決の訓練精度は97%。各モデルの平均よりは高そうですが、最もパフォーマンスの良かったロジスティック回帰を下回っています。もしかしたらモデルの中でパフォーマンスがあまりよくない決定木に足を引っ張られているのかもしれません。
一番下の多数決の訓練精度は97%。各モデルの平均よりは高そうですが、最もパフォーマンスの良かったロジスティック回帰を下回っています。もしかしたらモデルの中でパフォーマンスがあまりよくない決定木に足を引っ張られているのかもしれません。
 多数決の検証精度(一番下)は98%(!)。多数決に使った決定木からランダムフォレストのパフォーマンスを上回っており、みごとに多数決の成果が出ました。
多数決の検証精度(一番下)は98%(!)。多数決に使った決定木からランダムフォレストのパフォーマンスを上回っており、みごとに多数決の成果が出ました。

 最適値が変わりました。決定木込みでは6分割でしたが、決定木を除外すると5分割がベストです。精度も先ほどの95%から97%に上がりました。
最適値が変わりました。決定木込みでは6分割でしたが、決定木を除外すると5分割がベストです。精度も先ほどの95%から97%に上がりました。
 続いて検証。
続いて検証。
 多数決の訓練精度が98%、検証精度が99%(!)。やばいですね、メッチャ精度高いです。
多数決の訓練精度が98%、検証精度が99%(!)。やばいですね、メッチャ精度高いです。
 バージョンを経るごとに着実に精度が上がっており、最終的には決定木を除外した多数決がベストな機械学習モデルで、98.83%の精度が出ました。
バージョンを経るごとに着実に精度が上がっており、最終的には決定木を除外した多数決がベストな機械学習モデルで、98.83%の精度が出ました。
今回の乳がんAIで学んだことを簡単にまとめます。
乳がんAI第一弾はこちら


乳がん診断AIを作ってみる
機械学習③:各モデルで交差検証
やることの概要
前回、決定木とニューラルネットワークの2つのアルゴリズムについて最適なハイパーパラメータを求めました。ハイパーパラメータとは、ニューラルネットワークの階層数など、人間が決めなければならないパラメータです。決定木の階層数は6階層、ニューラルネットワークの活性化関数はIdentity・ソルバーはLbfgs・パーセプトロン数と階層は500個を3階層というのが前回求めたハイパーパラメータでした。まずは、決定木・ニューラルネットワーク・ロジスティック回帰・ランダムフォレストの機械学習アルゴリズムに対して、機械学習の訓練データと検証データを入れ替えながら学習することで精度を高める交差検証を試してみます。各アルゴリズムの概要や交差検証については、ソムリAIで解説していますので興味のある方は見てみてください(下にリンクを貼っています)。
交差検証(訓練精度)
早速交差検証をやってみます。前回からの続きでやっているため、実際にプログラムを動かしてみたい方は前回の冒頭に書いたデータ読込から順にコードを実行してください(データ読込や、説明変数・目的変数に分割してある状態から始めます)。ソムリAIの時と同様、決定木・ロジスティック回帰・ニューラルネットワーク・ランダムフォレストのモデルを定義して、交差検証用の関数に放り込みます。データの分割数は3分割~10分割として交差検証を行い、最適な分割数を求めようと思います。
決定木とニューラルネットワークについては、前回探索したハイパーパラメータを設定しています。ロジスティック回帰については適当に設定したパラメータで結果的に精度が出たのでそれを使っています。ランダムフォレストはフォレスト(森)に使う決定木の本数が多いほど精度が出るのでとりあえず100本にしています。
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neural_network import MLPClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.pipeline import Pipeline
from sklearn.model_selection import cross_val_score
#モデル1:決定木
clf1 = DecisionTreeClassifier(max_depth=6,random_state=0)
#モデル2:ロジスティック回帰
clf2 = LogisticRegression(solver='lbfgs', C=0.1, random_state=0)
pipe2 = Pipeline([['sc', StandardScaler()],['clf', clf2]])
#モデル3:ニューラルネットワーク
clf3 = MLPClassifier(activation='identity', solver='lbfgs', random_state=0, hidden_layer_sizes=(500,500,500,500))
pipe3 = Pipeline([['sc', StandardScaler()],['clf', clf3]])
#モデル4:ランダムフォレスト
clf4 = RandomForestClassifier(n_estimators=100, min_samples_leaf=3, random_state=0)
#各モデルの名称をリストに格納
clf_labels = ['Decision Tree', 'Logistic Regression', 'Neural Network', 'Random Forest']
#各モデルに対して交差検証を行い結果を表示
for clf, label in zip([clf1, pipe2, pipe3, clf4], clf_labels):
print("[%s]" % (label))
for i in range(3,11):
scores = cross_val_score(estimator=clf, X=X_train, y=Y_train, cv=i)
print("分割数%i 訓練精度と標準偏差: %0.4f (+/- %0.2f)"
% (i, scores.mean(), scores.std()))
実行結果が見づらかったのでエクセルで加工したものを掲載します。交差検証(検証精度)
訓練データに対してそれなりの精度が出たので、検証データに対して作ったモデルを適用してみます。訓練データでモデルを作って、訓練で使っていない検証データにモデルを適用することでモデルの汎化性能(モデルにとって未知のデータに対してもパフォーマンスが出るのか)を測るのです。from sklearn import metrics
#分割数6で学習し直し
#(ループを回して分割数を探索したので、現在のモデルは分割数10のモデルになっているため)
for clf, label in zip([clf1, pipe2, pipe3, clf4], clf_labels):
scores = cross_val_score(estimator=clf, X=X_train, y=Y_train, cv=6)
#各モデルの検証精度を測定
for clf, label in zip(all_clf, clf_labels):
clf.fit(X_train,Y_train)
Y_pred = metrics.accuracy_score(Y_test, clf.predict(X_test))
print("検証精度: %0.4f [%s]" % (Y_pred, label))
途中経過
色々やってきたので一旦、途中経過をまとめてみます。決定木とニューラルネットワークについては交差検証でパフォーマンスが向上しませんでした。。元の精度が高いからかもしれません。空欄の「多数決」と「決定木を除外した交差検証」はこのあとやっていきます。
機械学習④:多数決
ソムリAIでも使った多数決を適用してみます。ざっくり言うと、「複数の機械学習モデルのいいとこどりをして精度を高める」というものです。多数決で使うMajorityVoteClassifierというアルゴリズムは、『Python 機械学習プログラミング』という本で紹介されています。著作権の関係でアルゴリズムのコードは掲載しないので、中身を知りたい方はこちらをどうぞ。
多数決でいいとこどりをする(訓練精度)
先ほどの交差検証に多数決のモデルを定義して実行してみます。交差検証の分割数(8行目のcv)は、先ほどの結果を踏まえて6分割にしています。#MajorityVoteClassifierを使って多数決してみる
#モデルの定義
mv_clf = MajorityVoteClassifier(classifiers=[clf1, pipe2, pipe3, clf4])
#多数決モデルをループさせるリストに追加
clf_labels += ['Majority Voting']
all_clf = [clf1, pipe2, pipe3, clf4, mv_clf]
#各モデルに対して交差検証を行い訓練精度を表示
for clf, label in zip(all_clf, clf_labels):
scores = cross_val_score(estimator=clf, X=X_train, y=Y_train, cv=6)
print("訓練精度と標準偏差: %0.4f (+/- %0.2f) [%s]"
% (scores.mean(), scores.std(), label))

多数決でいいとこどりをする(検証精度)
検証精度の測定は、先ほどの交差検証と同じなのでコードは割愛します。途中経過
多数決の結果を一覧に追加しました。精度の高さでは多数決がトップなのです。

機械学習⑤:交差検証・多数決(決定木除外)
先ほどの交差検証の訓練精度ではロジスティック回帰・ニューラルネットワーク・ランダムフォレストは95%を超えていたものの、決定木は92%程度の精度でした。足を引っ張っている決定木を除外すると交差検証と多数決のパフォーマンスが変わるかもしれないので、決定木を除外してもう一度やってみます。決定木を除外した交差検証
決定木関連のコードを削除しただけで、やっていることは先ほどと同じです。#決定木を除外した交差検証
#モデル2:ロジスティック回帰
clf2 = LogisticRegression(solver='lbfgs', C=0.1, random_state=0)
pipe2 = Pipeline([['sc', StandardScaler()],['clf', clf2]])
#モデル3:ニューラルネットワーク
clf3 = MLPClassifier(activation='identity', solver='lbfgs', random_state=0, hidden_layer_sizes=(500,500,500,500))
pipe3 = Pipeline([['sc', StandardScaler()],['clf', clf3]])
#モデル4:ランダムフォレスト
clf4 = RandomForestClassifier(n_estimators=100, min_samples_leaf=3, random_state=0)
#各モデルの名称をリストに格納
clf_labels = ['Logistic Regression', 'Neural Network', 'Random Forest']
#各モデルに対して交差検証を行い結果を表示
for clf, label in zip([pipe2, pipe3, clf4], clf_labels):
print("[%s]" % (label))
for i in range(3,11):
scores = cross_val_score(estimator=clf, X=X_train, y=Y_train, cv=i)
print("分割数%i 訓練精度と標準偏差: %0.4f (+/- %0.2f)"
% (i, scores.mean(), scores.std()))
決定木を除外した多数決
先ほどの交差検証の結果で得られた5分割で多数決を行います。訓練・検証一気にやっちゃいます。先ずは訓練から。#MajorityVoteClassifierを使って多数決してみる
#決定木除外・交差検証5分割
#モデルの定義
mv_clf = MajorityVoteClassifier(classifiers=[pipe2, pipe3, clf4])
#多数決モデルをループさせるリストに追加
#各モデルの名称をリストに格納
clf_labels = ['Logistic Regression', 'Neural Network', 'Random Forest','Majority Voting']
all_clf = [pipe2, pipe3, clf4, mv_clf]
#各モデルに対して交差検証を行い訓練精度を表示
for clf, label in zip(all_clf, clf_labels):
scores = cross_val_score(estimator=clf, X=X_train, y=Y_train, cv=5)
print("訓練精度と標準偏差: %0.4f (+/- %0.2f) [%s]"
% (scores.mean(), scores.std(), label))

from sklearn import metrics
#各モデルの検証精度を測定
for clf, label in zip(all_clf, clf_labels):
clf.fit(X_train,Y_train)
Y_pred = metrics.accuracy_score(Y_test, clf.predict(X_test))
print("検証精度: %0.4f [%s]" % (Y_pred, label))
まとめ
今回の乳がんAIのパフォーマンスの総括は以下の通りです。
今回の乳がんAIで学んだことを簡単にまとめます。
- データの1明細に含まれる項目数(要素数)が多い方が機械学習の精度が高まるのかもしれない(ソムリAIの1明細あたりの項目数は10程度だったが、乳がんAIは30)。
- データの総数は機械学習の精度にあまり影響しないのかもしれない(ソムリAIは1600明細あったが、乳がんAIは570明細たらず)。
- ロジスティック回帰やランダムフォレストなど複数のアルゴリズムで精度の高いモデルが作れた場合、それを多数決に放り込むといいとこどりしてもっと精度の高いモデルが作れる。
- 決定木は精度が上がりにくいが、AIの中身が見える化できる点がメリット(決定木はどの項目に注目してどう判断しているかが見えるが、それ以外のモデルはブラックボックス)。




























